
.jpg)



Anonymisation et pseudonymisation sont les enjeux techniques majeurs de l’open data des décisions de justice. Entretien avec Noémie Marciano et Laura Delmas, les “techs” en charge de cette mission chez Predictice.

Laura Delmas est linguiste computationnelle chez Predictice depuis un an et demi. Elle est en charge de la détection d’entités nommées complexes (détection des entreprises, des cabinets d’avocats…) grâce à des techniques de traitement automatique des langues et de machine learning, et s’occupe également à l’occultation des noms dans les décisions présentes dans la base de données de Predictice.

Noémie Marciano est data scientist chez Predictice depuis un an et demi. Spécialisée dans la détection et la compréhension des chefs de demande, elle s’est ensuite occupée de la détection des sections des décisions grâce aux techniques de deep learning, ainsi que de l’occultation des adresses présentes dans les décisions de justice.
Predictice a lancé le programme “100 000 décisions de justice inédites”, afin de recueillir et de mutualiser des décisions de première instance. Cette initiative a pour finalité de créer une base de données inédites en France. Elle a aussi pour conséquence d'augmenter votre charge de travail sur l'occultation. Quels challenges techniques se cachent derrière cette initiative ?
Pour comprendre les distinctions entre occultation, anonymisation et pseudonymisation, lire : Open data des décisions de justice : les nouvelles avancées
Le premier challenge est l’OCRisation (Optical Character Recognition) : il s'agit de la transformation d'une image, d'un texte imprimé en un fichier de texte. En effet, lorsqu’une décision est scannée, le résultat que nous, nous récupérons, n’est pas nécessairement un texte, il s’agit parfois d’une photographie. Il faut donc reconnaître les caractères à l’intérieur d’une image. Il arrive souvent aussi que les documents qui nous sont confiés soient détériorés par des annotations, des taches de café, qu’ils comportent des fautes de frappe… Cela génère un “bruit” que la machine va interpréter comme des caractères et rendre ainsi plus difficile la détection des noms et des adresses.
Le deuxième challenge est la détection des personnes et des adresses à proprement parler. Ainsi une adresse étrangère présentera une autre syntaxe qui rend sa détection plus complexe ; il en va de même pour les noms étrangers : un prénom étranger pourrait correspondre à un tout autre mot en français, ce qui complique la tâche.
Le troisième challenge est celui d’unifier les personnes au sein d’un même document. Ainsi, si l’on prend Laura Delmas comme exemple, ce nom peut être formulé de nombreuses façons différentes : Mme Delmas épouse Durand, Delmas Laura, Laura Delmas, Mme Durand… Il faut donc apprendre à la machine qu’il s’agit à chaque fois de la même personne, afin que son occultation soit toujours identique (Mme Axxx par exemple).
Le quatrième challenge naît de ce qu’il n’y a aucune marge d’erreur possible : il suffit que la machine ne détecte pas une seule occurrence du nom pour que tout le travail d’occultation soit mis en péril.
LIRE AUSSI >> Open data : le Conseil d'État impose la fixation d'un calendrier
L’occultation des décisions est imposée par les textes, notamment par le décret n° 2020-797 du 29 juin 2020 relatif à la mise à la disposition du public des décisions des juridictions judiciaires et administratives. Concrètement, comment faites-vous pour occulter les décisions que les avocats confient à Predictice ?
Chez Predictice, l’occultation est la première étape de traitement de tous les documents qui nous sont confiés.
Pour cela, nous utilisons un modèle de langage entraîné avec un corpus de français très riche, qui nous permet d’extraire des informations morphosyntaxiques. À partir de ces modèles, nous créons des règles pour l’occultation. Grâce à ces modèles de reconnaissance et ces règles, nous détectons les noms et prénoms des personnes physiques, leurs adresses et potentiellement leurs emails.

L’illustration ci-dessus montre les différentes étapes du travail d’occultation :
- la mise en place de l’OCR, c’est-à-dire la reconnaissance de caractères, que nous avons déjà évoquée ;
- ensuite nous faisons correspondre les noms et les adresses avec les modèles de langage, les règles et les dictionnaires connus par la machine ;
- l’étape suivante consiste à standardiser les noms et les adresses, en précisant le titre, le prénom, le nom ;
- avec la troisième étape, le linking, nous faisons comprendre à la machine que “Jean Dupont” en haut du texte est la même personne que M. Dupont cité dans un autre paragraphe ;
- une étape de recherche d’erreurs s’impose ensuite, en raison des inconsistances du texte que nous avons évoquées (erreurs de typographie, taches…) ;
- ensuite nous appliquons le même “masque” (Mme Axxx) à toutes les occurrences du nom qui ont été détectées ;
- enfin, la dernière étape consiste en une correction manuelle qui permet de corriger immédiatement les erreurs.
Voici un exemple de décision occultée par nos algorithmes :
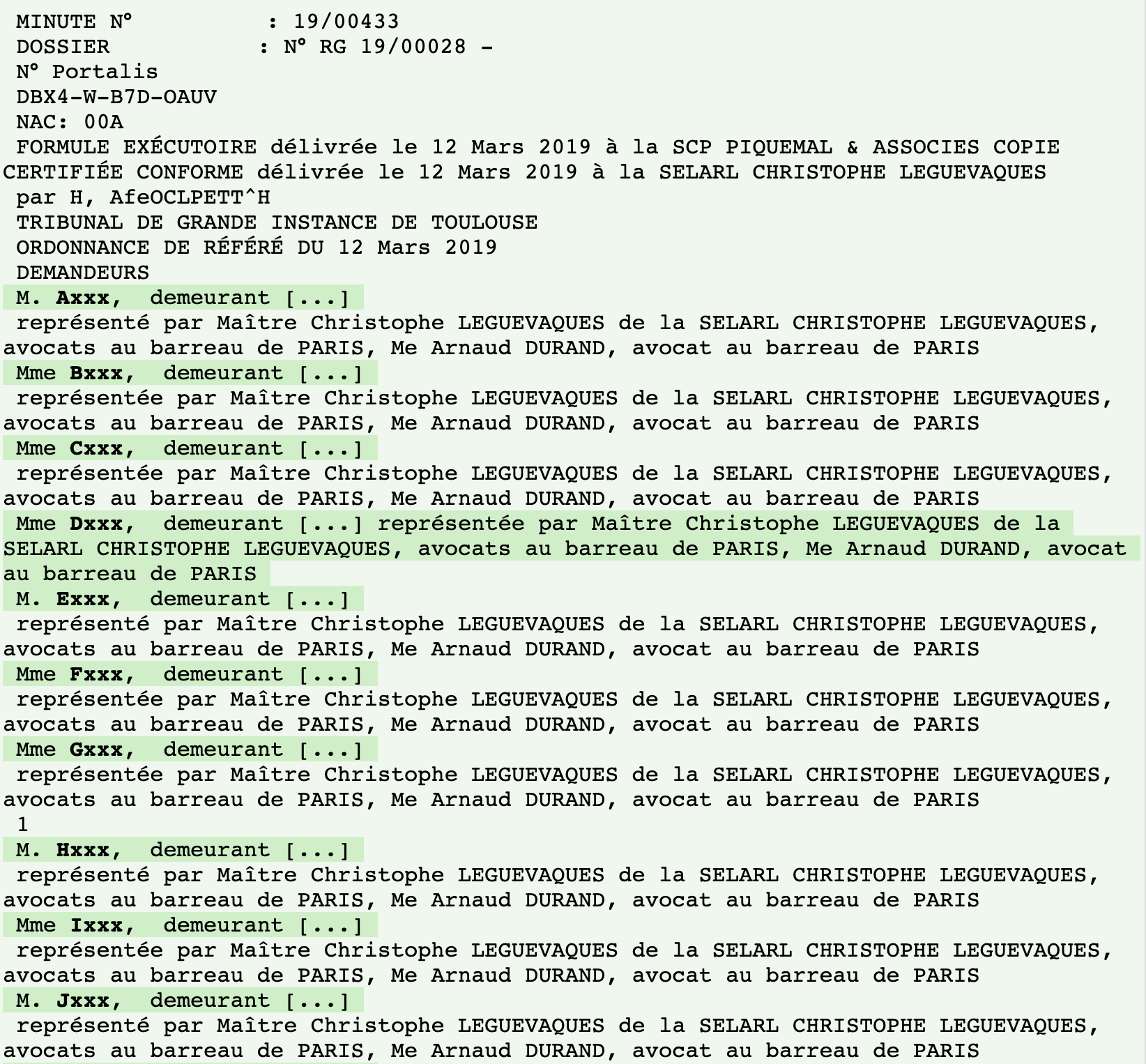
Le terme d’occultation recouvre différents niveaux : de la pseudonymisation, qui consiste en la simple suppression des noms et prénoms des parties et des tiers mentionnés dans la décision, à l’anonymisation, qui consiste à occulter tout élément permettant l’identification, à quel niveau de confidentialité se situe le travail d’occultation de Predictice ?
Nous travaillons sur un niveau de confidentialité élevé et qui concerne toutes les décisions qui figurent dans la plateforme : au-delà de la simple pseudonymisation, nous nous attachons à supprimer également toutes les adresses postales et électroniques figurant également dans les décisions.
Conformément à ce qui avait été préconisé par le rapport Cadiet, chez Predictice, nous avons fait le choix de ne pas occulter les références aux experts juridiques (magistrats, membres du greffe, avocats), ainsi que celles relatives aux personnes morales.
LIRE AUSSI >> Le filtre par entreprise, la nouvelle arme des professionnels du droit

%20(1).jpg)

.png)
.jpg)
.jpg)